(Python3) Sequences of Characters
December 07 2019
Python3에서 Unicode를 어떻게 다루는지 공부했던 것들을 기록해본다.
Abstract
다국어 프로그램을 다루기 위해서는 unicode에 대한 이해가 필수적이다.
(ASCII -> ANSI -> Unicode)
사실 네이버로 이직한 이후로는 쭉 백엔드 웹서버 개발만 하기 때문에
지금은 unicode를 고려하고 구현할일이 없다.
옛날 TmaxOS 개발에 참여했을 당시에는 나라별로 미리 정의된 다른 메세지를
보여주어야 했었는데, 그때 유심히 본 기억이 있다.
아무튼 Python3에서 unicode와 관련한 가장 중요하고
간단한 사실은 str은 unicode를 저장한다는 점이다.
Unicode
Unicode standard는 문자를 0x0부터 0x10FFFF 사이의 code point들로 표현하는
방법을 정의한다. unicode를 다루는 포스트에서 110만(0x10FFFF=1,114,111)이라는
숫자가 자주 등장하는 이유가 여기있다. 즉, Unicode는 sequence of code points이며
각 code point는 sequence of byte로 encoding된다.
아래의 예는 Unicode 문자열 "hello"를 UTF-8로 encoding하는 과정을 보여준다.
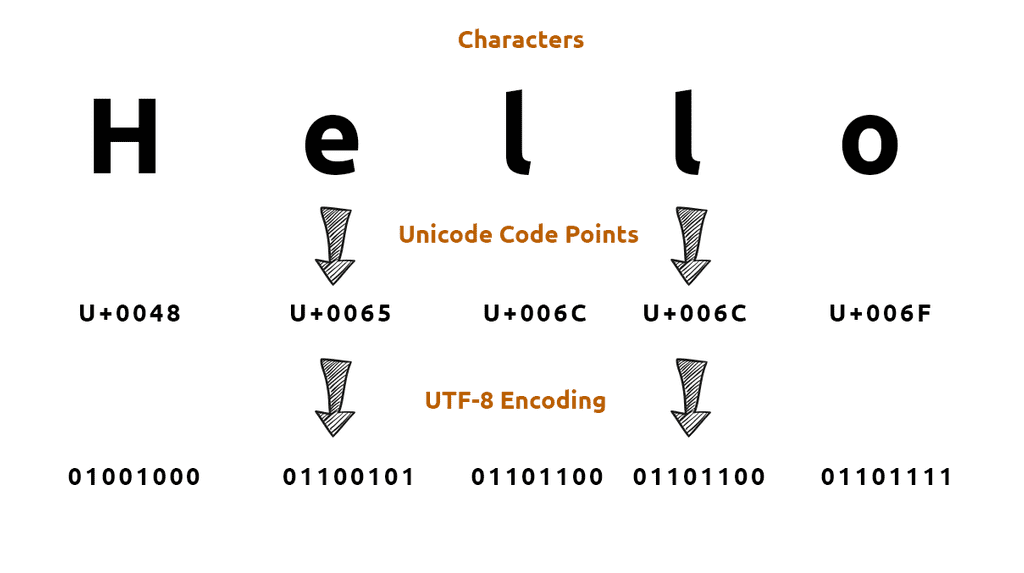
In Python
Python3에서 문자열(sequence of characters)을 표현하는 방법은
str와 bytes 두가지이다. (참고. Python2는 unicode와 str)
-
Two types that reprsent sequences of characters in Python3
str: unicode chracters를 저장bytes: raw 8-bit을 저장
Python3의 str은 unicode를 저장하는 용도로 사용된다.
따라서 unicode 문자열을 만드는 방법은 아주 쉽다.
single/double/triple-quote로 정의한 string literal은 모두 unicode string이다.
하나의 unicode character를 만들고 싶다면, chr()을 사용하면 되고, 해당하는
code point는 ord()를 통해 구할 수 있다.
또한, Python3에서는 소스코드의 기본 인코딩이 UTF-8이기 때문에 별도의 명시없이
unicode로 문자열을 정의할 수 있다. Identifier에도 unicode를 사용할 수
있기 때문에 아래의 코드도 문제없이 실행된다.
Type "help", "copyright", "credits" or "license" for more information.
>>> 주호 = 'jooho'
>>> print(주호)
joohobytes는 unicode가 아닌 1byte로 표현되는 문자들을 저장하기위한
용도로 사용된다. (Python2와 달리) bytes라는 이름이 "byte들"을 의미한다는
점에서 이해하기 쉽다. str과 bytes를 다룰 때는 encoding/decoding을
주의해서 사용해야한다.
- Should not assume anything about character encodings
-
Two common situations in Python code
- You want to operate on raw 8-bit values that are UTF-8 encoded characters
- You want to operate on Unicode characters that have no specific encoding
따라서 아래와 같이 str/bytes 모두를 받아서 실수없이 str/bytes로
바꿔주는 helper 함수가 필요할 수도 있다.
def to_str(bytes_or_str):
if isinstance(bytes_or_str, bytes):
value = bytes_or_str.decode(‘utf-8’)
else:
value = bytes_or_str
return value # Instance of str
def to_bytes(bytes_or_str):
if isinstance(bytes_or_str, str):
value = bytes_or_str.encode(‘utf-8’)
else:
value = bytes_or_str
return value # Instance of bytesProblems in Python2
(곧 Python2는 deprecated되지만)
Unicode와 관련된 Python2에의 첫번째 문제점은
ASCII 문자열이 저장된 str의 경우, encode() 결과도 여전히 str이라는 점이다.
따라서 ASCII 문자열만이 정상동작하고, 그렇지 않은 경우
예상과 달리 동작하는 함수를 만들 수 있다. Python3의 경우 empty string 조차도
str과 bytes는 전혀 다른 type이다.
두번째 문제점은 file operation들이 기본 binary encoding이라는 점이다. 따라서 Unicode로 작성된 파일을 읽고/쓰는데 불편했지만, Python3에서는 기본 UTF-8 encoding이 적용된다. Python3에서는 binary로 읽고/쓰기 위해서는 'rb', 'wb'로 mode를 명시해주어야한다.
Summary
-
Python 3
bytes: sequences of 8-bit values.str: sequences of Unicode characters.bytes!=str
-
Python 2
strcontains sequences of 8-bit values.unicodecontains sequences of Unicode characters.str==unicodeif thestronly contains 7-bit ASCII characters.
- Binary data to/from a file: binary mode ('rb' or 'wb').
Reference
- python.org
- Effective Python